这是「自建 Lakehouse 实战」系列第六篇。前五篇都在查(搭建、互操作、性能、联邦、扩容),这一篇换到写:数据怎么实时进湖?
业务库(MySQL/PostgreSQL)里的增删改,怎么以秒级延迟同步进数仓,还要能自动跟上源表的 schema 变更?这正是 CDC(Change Data Capture)要解决的问题。
这次的链路:
MariaDB (mariadb-operator) ─┐ ├─ Flink CDC 3.6 YAML pipeline ──→ Doris 存算分离 UNIQUE 内部表PostgreSQL (CNPG, wal=logical)─┘ (Flink standalone session 集群)直接给三个结论:
- CDC 端到端延迟几乎只由 Doris sink 的
buffer-flush.interval决定,跟源是 MySQL 还是 PG、跟你加几个节点,都没关系。 - 加 BE 能提吞吐(sub-linear),但对延迟完全无效;加 FE 对 CDC 基本没用。
- 增删改、upsert、全量快照两边都开箱即用;唯一的分叉点是 schema 演进 —— MySQL 开箱,PostgreSQL 必须显式开开关,否则直接挂。
一、为什么这套选型
- MariaDB:用官方
mariadb-operator(CRDk8s.mariadb.com),声明式管理实例 + binlog 配置。版本特意选 10.11 LTS 而非 11.x —— 新版 MariaDB 的 GTID 实现和 Debezium 的 MySQL 连接器有兼容雷,10.11 的 binlog 与 Flink CDC 的 mysql 连接器完全兼容。CDC 必须开binlog_format=ROW+binlog_row_image=FULL(UPDATE/DELETE 才带完整前像)。 - PostgreSQL:复用前几篇就在的 CloudNativePG operator,新建一个专用库,
wal_level=logical,逻辑解码插件用内置的pgoutput(PG 10+ 自带,不用装 wal2json/decoderbufs)。表要设REPLICA IDENTITY FULL。 - Flink CDC 3.6:关键是用 YAML pipeline 模式而不是老的 SQL connector —— 只有 pipeline 模式的 Doris sink 支持自动 schema 演进。值得一提:PostgreSQL 的 pipeline 连接器从 3.5.0 才有,3.6.0 起按 Flink 版本分叉(
3.6.0-1.20对应 Flink 1.20)。 - Doris 内部表:存算分离模式,数据落对象存储 storage vault。CDC 目标表用
UNIQUE KEY模型 —— 这正好天然实现 upsert(主键重复即更新),配合 sink 的 delete sign 处理删除。Flink CDC 的 Doris sink 会自动建表:UNIQUE KEY(主键) DISTRIBUTED BY HASH(主键) BUCKETS AUTO。
二、场景:增删改 / upsert / schema 演进

在两个源上分别跑了一整套:
- 全量快照
一提交就把存量数据灌进 Doris,✓。 - INSERT / UPDATE / DELETE:源表改完,Doris 侧 UNIQUE 表对应行增/改/删,✓。删除走 Doris 的
__DORIS_DELETE_SIGN__,merge-on-write 生效。 - upsert
的 INSERT ... ON DUPLICATE KEY UPDATE、PostgreSQL 的INSERT ... ON CONFLICT DO UPDATE,命中改、未命中插,都正确落到 UNIQUE 表,✓。
唯一两边不一样的,是 schema 演进(给源表 ALTER TABLE ADD COLUMN):
- MariaDB:开箱即用。 binlog 里原生带 DDL,Flink CDC 捕获后自动给 Doris 表
ALTER TABLE ADD COLUMN,新列 + 新数据无缝跟上。 - PostgreSQL:默认直接挂。
pgoutput不复制 DDL。你加完列再插一条带新列的数据,这条 6 字段的记录撞上 pipeline 里登记的 5 字段 schema,直接抛IllegalStateException: Column size does not match the data size,整个 job 失败。解法是显式给 postgres 源加schema-change.enabled: true—— 开了之后,它靠 pgoutput 在结构变化时发的 relation 消息把新列带出来,就能正常演进了。
这是从 MySQL 迁 CDC 经验到 PostgreSQL 时最容易栽的一个坑:别假设 PG 的 schema 演进跟 MySQL 一样自动。
三、延迟:被 sink 刷新间隔主导,跟源、跟节点都无关
测法:源表插一行(记录提交时刻),紧轮询 Doris 直到可见,算差值。一开始测出来 MariaDB 和 PostgreSQL 都是 ~9.6 秒,高得反常,而且两个源几乎一模一样。
排查发现:延迟既不是源的解码延迟,也不是 checkpoint 间隔,而是 Doris sink 的 sink.buffer-flush.interval(默认 10 秒) 在卡。日志里那一串 bufferMap is empty, no need to flush 每 10 秒一次,就是它。把它调到 1 秒,延迟立刻掉到 ~2.5 秒:
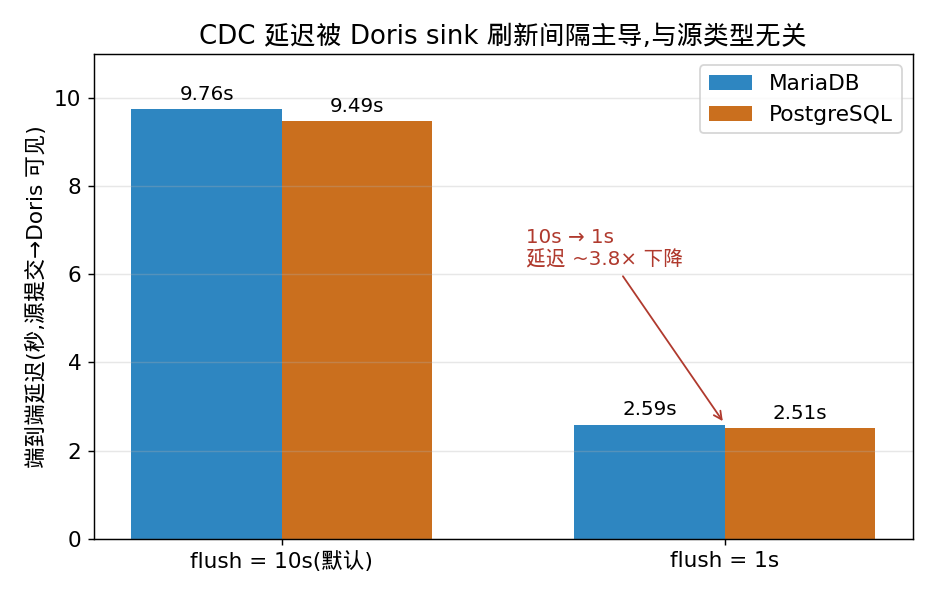
| flush interval | MariaDB | PostgreSQL |
|---|---|---|
| 10s(默认) | 9.76s | 9.49s |
| 1s | 2.59s | 2.51s |
两个源在同一档下几乎重合,证明延迟是 sink 侧的地板,与源类型无关。残留的 ~2.5s 是 1s flush + checkpoint 交互 + stream load 可见性 + 轮询粒度叠起来的。
要低延迟,调小
sink.buffer-flush.interval,而不是加机器。 代价是更频繁的 stream load(更多小事务、更碎的版本),要在延迟和 Doris compaction 压力之间权衡。
四、FE / BE 节点数的影响
存算分离的卖点是算力独立伸缩。那对 CDC 摄入来说,加 FE、加 BE 各有什么用?把 Doris 的 FE 从 1 扩到 3、BE 从 2 扩到 4,在同一条 pipeline(parallelism=4、flush=1s)上测吞吐(30k 行突发 drain)和延迟:

- 吞吐(左)
2→4 暖跑约 +35%(3323→4495 rows/s)。这是 sub-linear 的 —— 受单条 binlog reader(源侧串行读)+ 目标表 bucket 数 + sink 并行度共同封顶。CDC 增量的天花板往往在源侧的单线程 binlog/WAL 读,不在 Doris 写。图里我特意把两轮的散点也画上:轮间噪声有 ±40%(flush/checkpoint 周期相位对齐导致),所以 FE×3 那点 3821 落在噪声内,算不上提升。 - 延迟(右):三档配置 2210 / 2201 / 2206ms,一条直线。 加 FE、加 BE 对单行延迟完全无效 —— 因为延迟被 sink flush 地板卡死,跟有多少算力无关。
- FE 对 CDC 基本没用
只做 stream load 的协调和重定向(很轻),根本不是瓶颈。BE 才是真正落盘的。
一句话:要低延迟调 flush;要高吞吐加 BE(且记得给目标表多分 bucket);FE 别为 CDC 加。
顺带一个韧性观察:整个扩缩容过程(BE 2→4→2、FE 1→3→1)里,两条 pipeline 一直 RUNNING,Doris sink 在节点变动时自动重连,数据不丢 —— 测完源表 24 万行和 Doris 精确一致。
五、五个真实工程坑
这套链路不是一把跑通的,记下几个值得避的坑:
-
MySQL 驱动 GPL 不打包,而且要放对地方。 Flink CDC 因许可证不带
mysql-connector-j,报NoClassDefFoundError: com.mysql.cj.jdbc.Driver。更阴的是的 DriverManager在 JobManager 的 source coordinator 里用父类加载器找驱动,光把驱动 ship 到 TaskManager 的 child-first 类加载器没用 —— 必须把驱动塞进 Flink 的系统lib/(我直接FROM flink:1.20.4+COPY 驱动重打了个镜像)。(MariaDB 走 MySQL 协议,用 mysql 驱动即可。) -
checkpoint 默认没开,MySQL 增量永远不启动。 现象很迷惑:全量快照进来了,job 也 RUNNING,但源表后续的 binlog 一行都不同步。根因:MySQL 增量源在快照完成后,要等一次成功的 checkpoint 才会切到 binlog 读取。而 session 集群在 JobManager 上设的 checkpoint 间隔不会应用到通过 REST 提交的 job(job 的配置在客户端构建 JobGraph 时就定了)。解法:在客户端的 Flink 配置里显式开
execution.checkpointing.interval+checkpoints-after-tasks-finish.enabled: true(parallelism>1 时部分 source 子任务空闲,后一个标志必需)。 -
PostgreSQL 的
DEFAULT now()会让建表失败。 CreateTableEvent 把源列的updated_at DEFAULT now()原样带给 Doris,Doris 不认now()这个字面量,报date literal [now()] is invalid。去掉源列的 server 默认值即可。 -
route 的 TableId 段数 MySQL ≠ PostgreSQL。 mysql 源的 TableId 是两段
库.表;postgres 源的tables要写三段库.schema.表,但它发出的 TableId 却是两段schema.表(库名不进 TableId)。所以 route 的source-table必须按两段写,否则 sink 会拿源 schema 名当库名乱建库。 -
存算分离 FE 缩容要手动收尾。 实验完把 FE 从 3 缩回 1,operator 报
ScaleDownFailed、集群变 yellow —— 因为它不会自动把多余 FE 从选举组里摘掉(扩容时加的还是 OBSERVER,不是 follower)。手动ALTER SYSTEM DROP OBSERVER 'host:9010'之后,operator 立刻完成缩容、回 green。
(还有一个纯环境坑podman pull + kind load 进节点 —— 这个跟 CDC 无关,是本地 kind/podman 环境的老问题了。)
六、小结
- Flink CDC 3.6 的 YAML pipeline + Doris UNIQUE 内部表,是一套完整能用的实时入湖方案:增删改、upsert、schema 演进都覆盖,Doris 自动建表、自动演进。
- 延迟的旋钮是
sink.buffer-flush.interval,不是节点数:默认 10s,要秒级就往下调。 - 节点伸缩对 CDC 摄入
提吞吐(且受源侧单线程读封顶)、对延迟无效;FE 没用。 - MySQL → PostgreSQL 迁移时最大的认知差是 schema 演进
binlog 带 DDL 开箱即用,PG pgoutput 不带 DDL,必须显式 schema-change.enabled。
至此,这个在 kind 上自建的 Lakehouse 从搭建、跨引擎互操作、读性能横评、联邦查询、弹性扩容,一路写到了实时入湖。六篇下来,它已经是一个能查、能写、能实时同步的完整数据平台了。
📚 本文是「自建 Lakehouse 实战」系列(共 6 篇):