这是「自建 Lakehouse 实战」系列第四篇。前三篇(搭建、互操作、性能)解决了”能用、能互通、谁读得快”。这一篇回答一个很实际的架构问题:
我有一份冷数据躺在 Iceberg/GCS 上(事实表),关系维表在 Doris 里。如果用 Trino 做联邦查询把两边 join 起来,性能会有多糟?如果太糟,是不是不如单独立一个专门查冷数据的 Doris?
直接给结论:冷数据 + 需要 join → 专用 Doris 直读 Iceberg 是更优解。 Trino 联邦只在”能整段下推的单表查询”上不亏;一旦把 Doris 的关系数据当 join 的一边,它的代价会随 join 复杂度迅速恶化。
一、三种跑法
给 Trino 加一个走 MySQL connector 的 doris catalog——Doris FE 本就讲 MySQL 协议(9030 端口),Trino 直接当它是 MySQL:
connector.name=mysqlconnection-url=jdbc:mysql://<doris-fe-host>:9030?useSSL=falseconnection-user=root然后对同一逻辑查询跑三种方式,数据集是 TPC-H SF10(lineitem 6000 万行,事实表在 Iceberg/GCS 上;orders/customer/nation/region 关系维表):
- FED(Trino 联邦)
读 Iceberg 事实表 + 经 MySQL 拉 Doris 维表,在 Trino 里 join。 - TRI(Trino 全 Iceberg):维表也放 Iceberg,纯 Trino。用来隔离”MySQL 拉取”这一步的成本。
- 专用 Doris
用外部 catalog 直读同一份冷 Iceberg 事实表 + 自身原生维表,全在 Doris MPP 里 join。
冷读口径
⚠️ 一个对结论很关键的资源不对称:这套 Doris 计算节点被限制在 8 核 / 16GB ×2,而 Trino 我特意放开——不限 CPU(可吃满 56 核)+ 32GB 堆 ×2。记住这点,因为下面 Doris 是用 1/7 的 CPU 在赢。
二、下推决定一切
联邦快不快,只看一件事:对 Doris 表的操作能不能被 Trino 整段下推过去。
单表聚合 / 过滤:完全下推。 SELECT count(*), sum(totalprice) FROM orders WHERE orderdate < … 会被 Trino 整句改写成一条 SQL 丢给 Doris 执行,Trino 只收回 1 行结果。这种查询联邦毫无损耗,甚至比 Trino 自己扫 GCS 还快。
join:不能跨 catalog 下推。 Trino 没法把 join 推给 Doris,只能把(谓词下推、列裁剪之后的)维表行经 MySQL 协议拉回自己这边再 join。更要命的是,MySQL connector 对单表只生成 一个 split = 单连接、单线程串行拉取,没有任何并行度。这是 connector 的结构性限制。
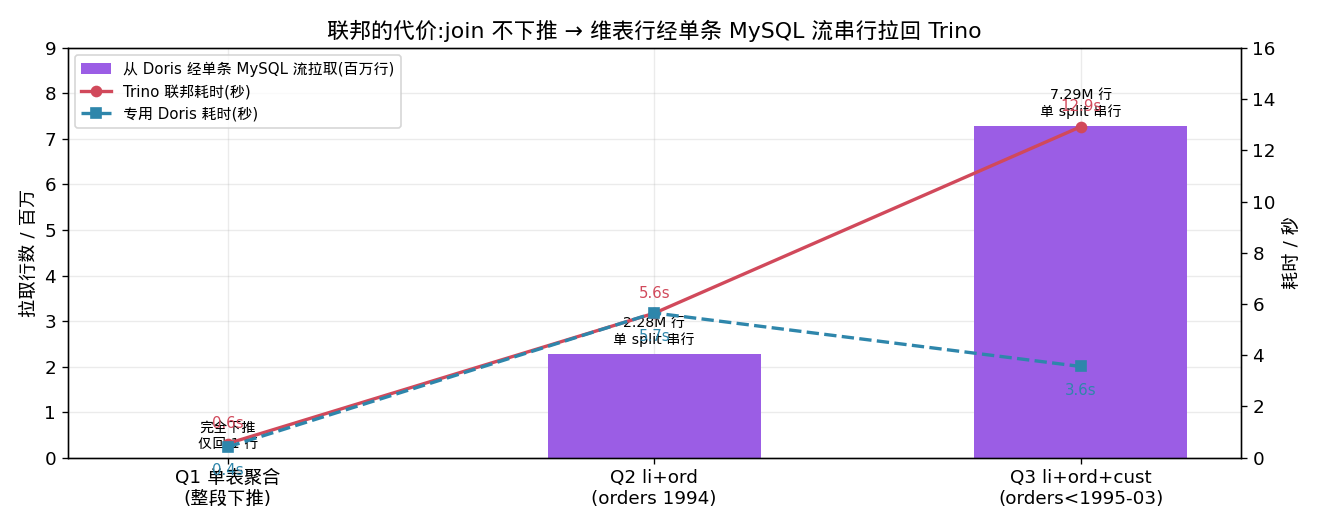
看这张图就懂了
三、冷读横评
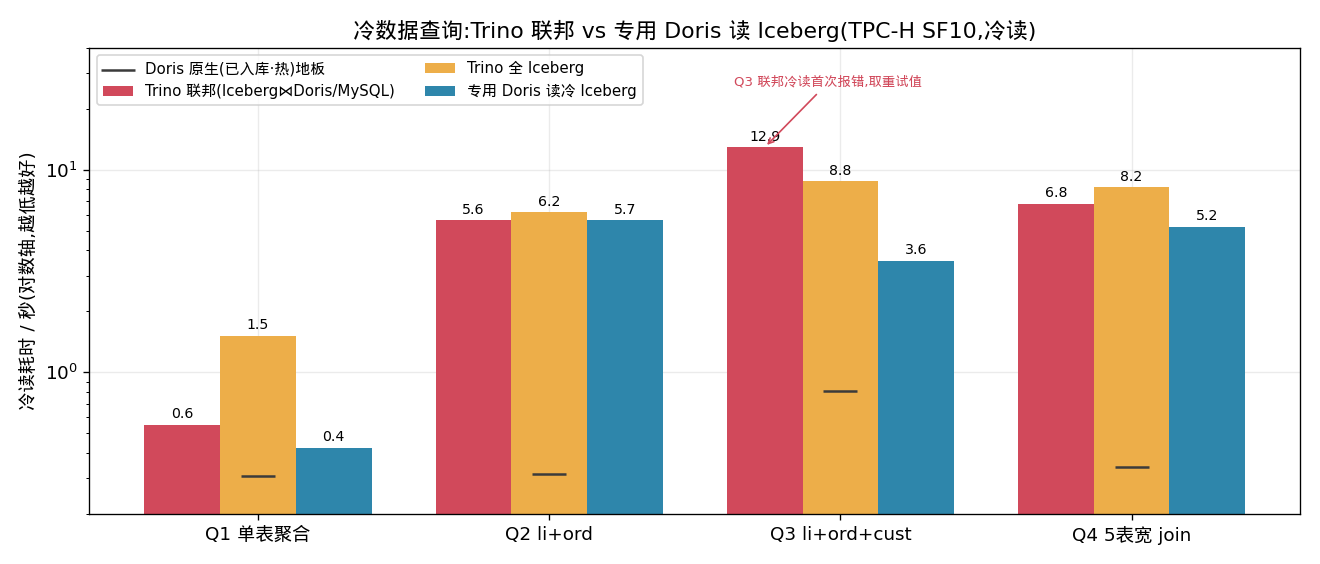
四个查询,join 由简到繁(对数轴,越低越好;灰色横杠是”数据已入库 Doris 原生·热”的地板):
| 查询 | Trino 联邦 | Trino 全 Iceberg | 专用 Doris 读冷 Iceberg | 谁赢 |
|---|---|---|---|---|
| Q1 单表聚合 | 0.6 | 1.5 | 0.4 | Doris |
| Q2 li+ord(冷扫描主导) | 5.6 | 6.2 | 5.7 | 平 |
| Q3 li+ord+cust | 报错→12.9 | 8.8 | 3.6 | Doris 快 3.6 倍 |
| Q4 5 表宽 join | 6.8 | 8.2 | 5.2 | Doris |
逐条看:
- Q2 三家打平(~5.6–6.2s):因为冷扫描 6000 万行 lineitem(1.5GB)从 GCS 拉回来是所有引擎的共同地板——物理带宽决定,谁都逃不掉。Q2 只从 Doris 拉 228 万行,被这个地板掩盖了。所以”冷数据查询”的下限,本质是对象存储的扫描速度;引擎之争,拼的是扫描之上的 join 与计算。
- Q3 是分水岭:要从 Doris 单线程拖 729 万行 orders,Trino 联邦 12.9 秒,而且冷读首次直接
RpcException报错、重试才出数——又慢又脆。专用 Doris 自己 MPP 读同一份冷 Iceberg + 本地维表,只要 3.6 秒。连 Trino 全 Iceberg(8.8s)都比联邦快,反证 MySQL 拉取那一步是纯负担。 - Q4 宽 join
默认配置( query.max-memory-per-node=1GB)下 5 表 join 直接 OOM,把 per-node 调到 20GB 才跑通(6.8s);专用 Doris 5.2s 拿下。
四、为什么专用 Doris 赢
两个原因叠加:
- 省掉跨引擎拉数。 联邦的本质是把维表数据”搬”到 Trino,而搬运通道是单条 MySQL 流。专用 Doris 直接在数据所在的引擎里 join,没有这趟搬运。
- 资源效率碾压。 别忘了 Doris 只有 8 核 ×2,Trino 不限 CPU(56 核)+ 32GB 堆 ×2。Doris 用 1/7 的 CPU 还全面更快——正经给它配资源会更夸张。
而”数据已入库 Doris 原生”的地板更是低到 0.3–0.8 秒(图里灰杠)。也就是说,如果冷数据值得反复查,把它 ingest 进 Doris 比任何 Iceberg 直读都快一个数量级。
五、那联邦什么时候还能用?
公平地说,Trino 联邦不是一无是处:
- 下推友好的查询(单表聚合、过滤、点查):整段推给 Doris,联邦零损耗,甚至更快(Q1)。
- 冷扫描完全主导、join 可忽略:大事实表全表扫,小维表点缀(Q2),联邦和专用引擎打平——反正瓶颈在 GCS 带宽。
- 真正的价值是”一个 SQL 跨多个数据源”的便利性,而不是性能。当你只是偶尔关联一下、数据量不大时,省去搬数据建表的功夫很香。
但只要满足”把另一个引擎里的大块关系数据当 join 的一边”,联邦就会被单线程 MySQL 拉取拖垮。
六、选型小结
- 冷数据 + 需要 join + 在意延迟 → 专用 Doris 直读 Iceberg(外部 catalog)。省掉跨引擎搬运,MPP 并行扫对象存储,本地维表零成本。这就是开头那个问题的答案:值得为冷数据单独立一个 Doris。
- 冷数据值得反复查 → 干脆 ingest 进 Doris 原生表,亚秒级。
- Trino 联邦 → 留给”跨源便利性 > 性能”的探索性查询,或能整段下推的单表分析。别拿它扛大维表 join。
- 一个反直觉但重要的点:冷数据查询的天花板是对象存储扫描速度,不是引擎。选型真正影响的是扫描之上的部分——而那恰恰是联邦最吃亏的地方。
所有数字都是在同一份 Lakekeeper/GCS 上的 Iceberg 表上跑出来的——开放表格式让”一份冷数据、多引擎按需取用”成为可能;而这一篇说明:取用的方式(联邦拉取 vs 引擎直读),对冷数据查询的体验差出好几倍。
📚 本文是「自建 Lakehouse 实战」系列(共 6 篇):