这是「自建 Lakehouse 实战」系列第五篇。前四篇都在横向比引擎(搭建、互操作、性能、联邦),这一篇换个角度,问一个调优问题:
存算分离最大的卖点之一,是算力可以独立伸缩。那么把 Doris 的 compute group 从 2 个 BE 扩到 8 个,查询到底能快多少?是线性加速,还是很快就撞墙?
直接给结论:加 BE 的收益强烈”双峰”——重计算/重 shuffle 的查询近线性加速,轻量亚秒查询几乎不动甚至变慢。该堆 BE 就堆,但要堆在对的负载上。
一、设置
- Doris 存算分离(compute-storage 分离),数据在 GCS storage vault,计算节点(BE)无状态、可秒级伸缩。扩容只改一个数:
computeGroups[0].replicas。 - 数据
SF10 原生表(lineitem 6000 万行,16 bucket)。每个 BE 限 8 核 / 16GB。 - 7 个查询,覆盖不同负载形态:纯扫描、TPC-H Q1(重聚合)、2/3/5 表 join、高基数 group by(6000 万行 join 后按 150 万 custkey 分组,重 shuffle)。
- 口径:热缓存(预热 2 轮,关掉 SQL/结果缓存只留数据缓存),所以测的是计算并行度而非 GCS 扫描带宽;每查询 best-of-3,再减去连接开销基线(本环境
SELECT 1往返 ~290ms,不减会严重压缩快查询的加速比)。 - BE 数从 2 一路扫到 8(含 3/5/6/7 这些非 2 的幂)。
二、双峰:重查询近线性,轻查询不动

净耗时(ms)与相对 2BE 的加速比:
| 查询 | 2 | 4 | 8 | 8BE 加速比 |
|---|---|---|---|---|
| S3 TPC-H Q1(重聚合) | 1370 | 675 | 319 | 4.3× |
| S7 高基数 group by(重 shuffle) | 3195 | 1124 | 810 | 3.9× |
| S4 join2 | 599 | 488 | 280 | 2.1× |
| S5 join3 | 434 | 348 | 290 | 1.5× |
| S6 join5 | 511 | 622 | 304 | 1.7× |
| S2 Q6 过滤扫描 | 143 | 128 | 107 | 1.3× |
- 重计算/重 shuffle 近线性甚至超线性
Q1 在 8 BE 跑出 4.3×(超过理想的 4×,多半来自热集分散到更多 BE 后单 BE 缓存命中更好);高基数 group by 3.9×。这类”可并行的活够多”的查询,堆 BE 直接见效。 - 轻量/亚秒查询几乎不动
/ join5 / 过滤扫描只有 1.3–1.7×,join5 在 4 BE 甚至变慢。 - 几何平均:4BE 1.42×、8BE 2.23×(理想 2×/4×)——但这个均值掩盖了上面强烈的分化。
三、为什么轻查询不动:协调地板
把所有点(2–8 BE)画出来看,会发现轻查询都压在一条水平线附近——本环境约 300ms。这是每个查询的固定成本:查询规划、fragment 派发、跨 BE 的数据交换(exchange)建立。这部分不随 BE 增多而减少,反而略增(BE 越多,exchange 的连接对越多)。
所以:亚秒级查询有一个加 BE 也打不破的延迟地板。当一个查询的”真正计算”只要一两百毫秒时,它整体耗时被这层固定开销主导,堆再多 BE 也只是让一群 BE 围着一点点活空转。要优化这类查询,该提升的是并发吞吐和缓存命中,不是 BE 数。
四、扫描受 bucket 数封顶
纯扫描类(全表 count+sum)在热缓存下已是 sub-150ms,加 BE 基本无感。一个结构性原因BUCKETS 16,扫描并行度最多 16 路;8 BE 时每个 BE 只摊到 ~2 个 lineitem tablet,8 核根本喂不饱。要让大扫描吃满更多 BE,得先把表分更多 bucket——否则桶数就是扫描并行度的天花板。(join/agg 的 shuffle 不受此限,它按核数重新分区。)
五、非 2 的幂会不会有奇怪现象?
我特意补了 3、5、6、7 这些非 2 的幂的点,担心 16 个 bucket 除不尽会造成分配失衡、出现 straggler。结果是:没有任何意外。
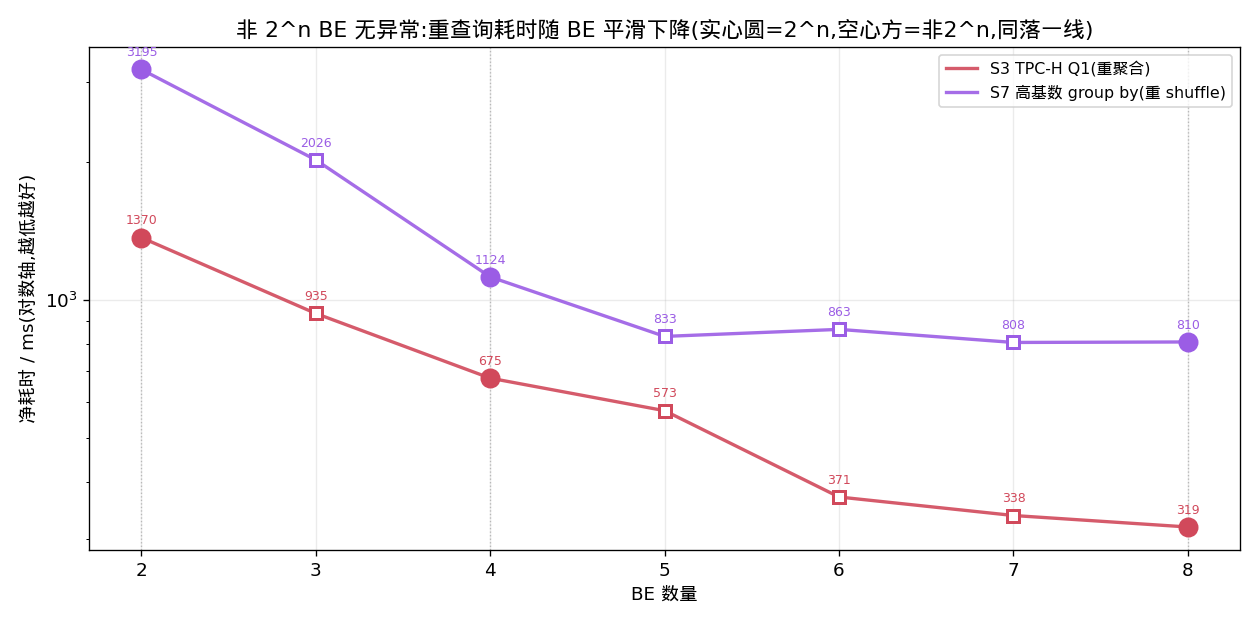
实心圆是 2 的幂(2/4/8),空心方块是非 2 的幂(3/5/6/7)——它们精确落在同一条平滑曲线上。原因是 Doris 存算分离的 tablet 缓存亲和性重平衡器,在任意 BE 数都把总 tablet 均分(3BE=31/30/30、5BE=19/18×4、7BE=13×7)。尽管单张 lineitem 的 16 桶除不尽 7,但跨所有表的总 tablet 仍然均衡,加上 shuffle 本就按核数均分,所以奇数 BE 不会失衡。
轻查询那几条线确实有上下抖动(比如 join2 在某个点突然偏快),但那是耗时贴着 300ms 地板时 best-of-3 的正常噪声,跟”是不是 2 的幂”无关。结论
六、调优小结
- 按主力查询的”重量”决定 BE 数,而不是某个魔法数字。 负载是大聚合 / 大 join / 高基数 group by → 堆 BE 近线性划算,一路扩到 8 都在降;负载是大量亚秒级点查 / 小 join → 扩 BE 几乎白花钱,该优化并发与缓存。
- 每查询有协调延迟地板(本环境 ~300ms),小查询别指望靠 BE 数突破。
- 扫描并行度被 bucket 数封顶,大扫描想吃满算力要先加桶。
- 不同查询的”拐点”不同也不在 2 的幂上:高基数 group by 的收益在 2→4 就基本吃完,TPC-H Q1 能一路扩到 8。先认识你的负载,再定规模。
存算分离让”按需加算力”变得很轻(改一个 replicas 数、秒级生效),但”加了就一定快”是个美好的误会——算力只对吃得下它的查询有意义。
📚 本文是「自建 Lakehouse 实战」系列(共 6 篇):